LangServe example
1. base.py
from abc import ABC, abstractmethod
class BaseChain(ABC):
"""
체인의 기본 클래스입니다.
모든 체인 클래스는 이 클래스를 상속받아야 합니다.
Attributes:
model (str): 사용할 LLM 모델명
temperature (float): 모델의 temperature 값
"""
def __init__(self, model: str = "exaone", temperature: float = 0, **kwargs):
self.model = model
self.temperature = temperature
self.kwargs = kwargs
@abstractmethod
def setup(self):
"""체인 설정을 위한 추상 메서드"""
pass
def create(self):
"""체인을 생성하고 반환합니다."""
return self.setup()
2. chains.py
(BaseChain을 이용하여 구현)
from langchain_ollama import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from typing import Optional
from base import BaseChain
class TopicChain(BaseChain):
"""
주어진 주제에 대해 설명하는 체인 클래스입니다.
Attributes:
model (str): 사용할 LLM 모델명
temperature (float): 모델의 temperature 값
system_prompt (str): 시스템 프롬프트
"""
def __init__(
self,
model: str = "exaone",
temperature: float = 0,
system_prompt: Optional[str] = None,
**kwargs,
):
super().__init__(model, temperature, **kwargs)
self.system_prompt = (
system_prompt
or "You are a helpful assistant. Your mission is to explain given topic in a concise manner. Answer in Korean."
)
def setup(self):
"""TopicChain을 설정하고 반환합니다."""
llm = ChatOllama(model=self.model, temperature=self.temperature)
prompt = ChatPromptTemplate.from_messages(
[
("system", self.system_prompt),
("user", "Here is the topic: {topic}"),
]
)
chain = prompt | llm | StrOutputParser()
return chain
class ChatChain(BaseChain):
"""
대화형 체인 클래스입니다.
Attributes:
model (str): 사용할 LLM 모델명
temperature (float): 모델의 temperature 값
system_prompt (str): 시스템 프롬프트
"""
def __init__(
self,
model: str = "exaone",
temperature: float = 0.3,
system_prompt: Optional[str] = None,
**kwargs,
):
super().__init__(model, temperature, **kwargs)
self.system_prompt = (
system_prompt
or "You are a helpful AI Assistant. Your name is '토니'. You must answer in Korean."
)
def setup(self):
"""ChatChain을 설정하고 반환합니다."""
llm = ChatOllama(model=self.model, temperature=self.temperature)
prompt = ChatPromptTemplate.from_messages(
[
("system", self.system_prompt),
MessagesPlaceholder(variable_name="messages"),
]
)
chain = prompt | llm | StrOutputParser()
return chain
class LLM(BaseChain):
"""
기본 LLM 체인 클래스입니다.
다른 체인들과 달리 프롬프트 없이 직접 LLM을 반환합니다.
"""
def setup(self):
"""LLM 인스턴스를 설정하고 반환합니다."""
llm = ChatOllama(model=self.model, temperature=self.temperature)
return llm
class Translator(BaseChain):
"""
번역 체인 클래스입니다.
주어진 문장을 한국어로 번역합니다.
Attributes:
model (str): 사용할 LLM 모델명
temperature (float): 모델의 temperature 값
system_prompt (str): 시스템 프롬프트
"""
def __init__(
self,
model: str = "exaone",
temperature: float = 0,
system_prompt: Optional[str] = None,
**kwargs,
):
super().__init__(model, temperature, **kwargs)
self.system_prompt = (
system_prompt
or "You are a helpful assistant. Your mission is to translate given sentences into Korean."
)
def setup(self):
"""Translator 체인을 설정하고 반환합니다."""
llm = ChatOllama(model=self.model, temperature=self.temperature)
prompt = ChatPromptTemplate.from_messages(
[
("system", self.system_prompt),
("user", "Here is the sentence: {input}"),
]
)
chain = prompt | llm | StrOutputParser()
return chain
1. ChatChain 클래스 구조
- 클래스 상속: ChatChain은 BaseChain(사용자가 정의했거나, 특정 라이브러리에서 제공되는 체인 기반 클래스)에서 상속받습니다.
- __init__ 생성자
- model: 사용할 LLM 모델(예: "exaone")
- temperature: 모델의 생성 다양성을 조절(기본값 0.3)
- system_prompt: 시스템 프롬프트, 제공되지 않으면 기본값이 "You are a helpful AI Assistant..."
- **kwargs: 나머지 인자를 부모 클래스(BaseChain)에 전달
- setup() 메서드
- ChatOllama 모델을 초기화 (llm)
- ChatPromptTemplate를 이용해 “system” 메시지와 “messages” 플레이스홀더(사용자 혹은 컨텍스트 메시지)로 구성된 프롬프트 템플릿(prompt)을 생성
- 최종적으로 chain = prompt | llm | StrOutputParser()로 연결한 체인을 반환
- 이 파이프라인은 LangChain의 “Runnable” 개념으로, 프롬프트 -> LLM -> 파서 단계를 순서대로 이어붙이는 구조입니다.
2. 인스턴스 선언 시 동작
# 예시
my_chat_chain = ChatChain(model="exaone", temperature=0.3)- 이 순간에는 아직 체인(chain) 자체가 구동되는 것은 아닙니다.
- 단지 __init__ 메서드를 통해:
- BaseChain의 초기화 로직을 수행
- model, temperature, system_prompt 등을 속성으로 저장
- system_prompt가 전달되지 않았다면 기본 메시지로 설정
즉, my_chat_chain 객체가 만들어졌을 뿐, 실제로 LLM, 프롬프트 템플릿 등을 연결한 체인은 setup()이 호출될 때 구성됩니다.
3. setup() 메서드 동작
chain = my_chat_chain.setup()- setup() 내부에서 다음이 수행됩니다:
- LLM 초기화: llm = ChatOllama(model=self.model, temperature=self.temperature)
- Ollama 기반 LLM을 선언하여, 체인 내에서 사용할 모델 객체를 생성합니다.
- 프롬프트 템플릿 구성:
- LLM 초기화: llm = ChatOllama(model=self.model, temperature=self.temperature)
prompt = ChatPromptTemplate.from_messages(
[
("system", self.system_prompt),
MessagesPlaceholder(variable_name="messages"),
]
)- 시스템 프롬프트(“system”)에 self.system_prompt 문자열을 사용합니다.
- 이후에 들어올 “messages” 부분은 MessagesPlaceholder로 설정해, 유저 메시지 등 여러 단계의 대화 내용을 여기에 동적으로 주입하게 됩니다.
- 체인 연결:
chain = prompt | llm | StrOutputParser()- 위에서 만든 prompt → llm → StrOutputParser() 순으로 파이프라인을 연결한 ‘최종 체인’(Runnable 형태)을 생성합니다.
- 체인 반환: return chain
이 과정을 통해 실제로 사용 가능한 LangChain 체인(Runnable 객체)이 만들어집니다.
4. 사용 예시
# 1) 객체 생성
my_chat_chain = ChatChain(model="exaone", temperature=0.3)
# 2) 체인 설정(생성)
chain = my_chat_chain.setup()
# 3) 체인 실행
result = chain.invoke({"messages": [("user", "안녕하세요, 오늘 날씨 어때요?")]})
print(result)
3. server.py
from fastapi import FastAPI
from fastapi.responses import RedirectResponse
from fastapi.middleware.cors import CORSMiddleware
import uvicorn
from typing import List, Union
from pydantic import BaseModel, Field
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langserve import add_routes
from chains import ChatChain, TopicChain, LLM, Translator
from rag import RagChain
from dotenv import load_dotenv
load_dotenv()
# FastAPI 애플리케이션 객체 초기화
app = FastAPI()
# CORS 미들웨어 설정
# 외부 도메인에서의 API 접근을 위한 보안 설정
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
expose_headers=["*"],
)
# 기본 경로("/")에 대한 리다이렉션 처리
@app.get("/")
async def redirect_root_to_docs():
return RedirectResponse("/chat/playground")
# translate 체인 추가
add_routes(app, Translator().create(), path="/translate")
# llm 체인 추가
add_routes(app, LLM().create(), path="/llm")
# topic 체인 추가
add_routes(app, TopicChain().create(), path="/topic")
# RAG 체인 추가
# file_path 파라미터 필요: 문서 경로를 지정합니다.
add_routes(
app,
RagChain(file_path="data/your_document.pdf").create(),
path="/rag",
)
########### 대화형 인터페이스 ###########
class InputChat(BaseModel):
"""채팅 입력을 위한 기본 모델 정의"""
messages: List[Union[HumanMessage, AIMessage, SystemMessage]] = Field(
...,
description="The chat messages representing the current conversation.",
)
# 대화형 채팅 엔드포인트 설정
# LangSmith를 사용하는 경우, 경로에 enable_feedback_endpoint=True 을 설정하여 각 메시지 뒤에 엄지척 버튼을 활성화하고
# enable_public_trace_link_endpoint=True 을 설정하여 실행에 대한 공개 추적을 생성하는 버튼을 추가할 수도 있습니다.
# LangSmith 관련 환경 변수를 설정해야 합니다(.env)
add_routes(
app,
ChatChain().create().with_types(input_type=InputChat),
path="/chat",
enable_feedback_endpoint=True,
enable_public_trace_link_endpoint=True,
playground_type="chat",
)
# 서버 실행 설정
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
4. rag.py
from typing import Optional
from langchain_core.output_parsers import StrOutputParser
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_community.vectorstores.faiss import FAISS
from langchain_core.prompts import load_prompt
from langchain_ollama import OllamaEmbeddings, ChatOllama
from base import BaseChain
# 문서 포맷팅
def format_docs(docs):
return "\n\n".join(
f"<document><content>{doc.page_content}</content><page>{doc.metadata['page']}</page><source>{doc.metadata['source']}</source></document>"
for doc in docs
)
class RagChain(BaseChain):
def __init__(
self,
model: str = "exaone",
temperature: float = 0.3,
system_prompt: Optional[str] = None,
**kwargs,
):
super().__init__(model, temperature, **kwargs)
self.system_prompt = (
system_prompt
or "You are a helpful AI Assistant. Your name is '테디'. You must answer in Korean."
)
if "file_path" in kwargs:
self.file_path = kwargs["file_path"]
def setup(self):
if not self.file_path:
raise ValueError("file_path is required")
# Splitter 설정
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
# 문서 로드
loader = PDFPlumberLoader(self.file_path)
docs = loader.load_and_split(text_splitter=text_splitter)
# 캐싱을 지원하는 임베딩 설정
EMBEDDING_MODEL = "bge-m3"
embeddings = OllamaEmbeddings(model=EMBEDDING_MODEL)
# 벡터 DB 저장
vectorstore = FAISS.from_documents(docs, embedding=embeddings)
# 문서 검색기 설정
retriever = vectorstore.as_retriever()
# 프롬프트 로드
prompt = load_prompt("prompts/rag-exaone.yaml", encoding="utf-8")
# Ollama 모델 지정
llm = ChatOllama(
model="exaone",
temperature=0,
)
# 체인 생성
chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
return chain
5. 구동 (server.py)
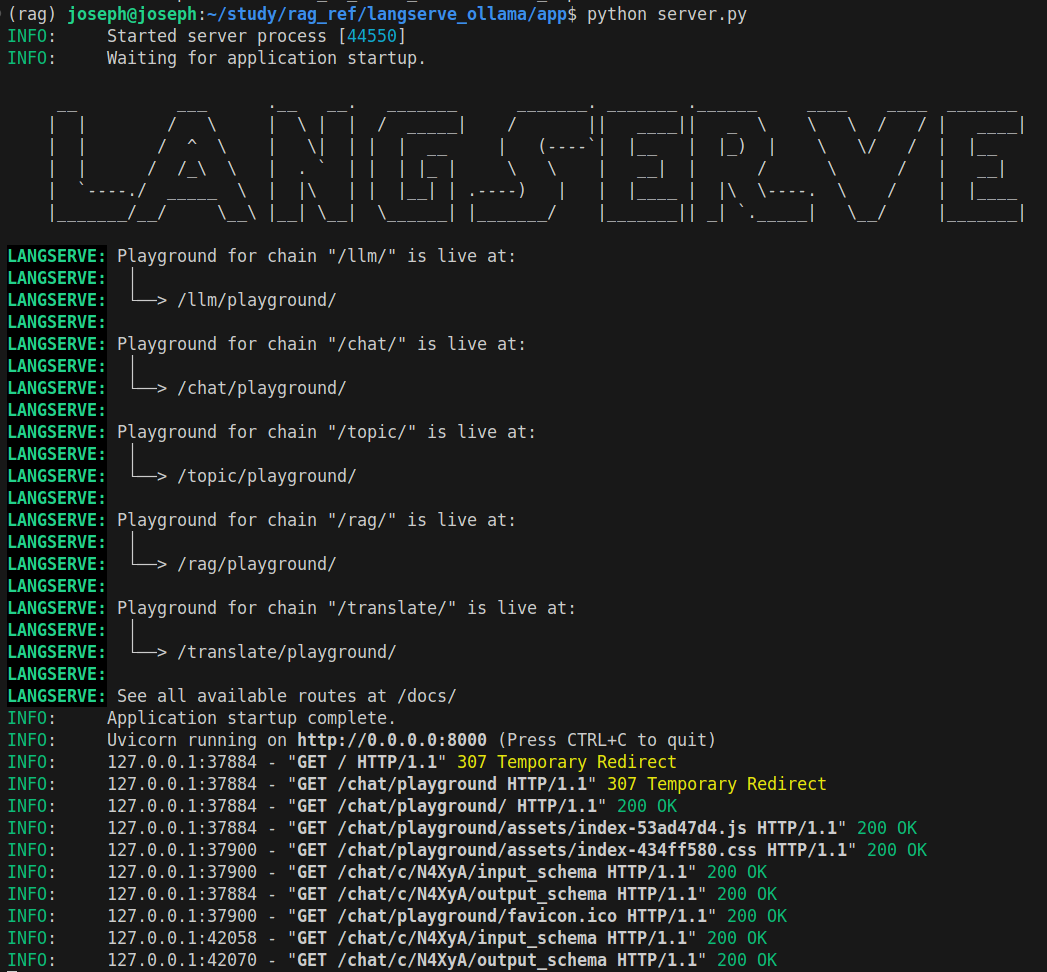
http://localhost:8000/chat/playground/
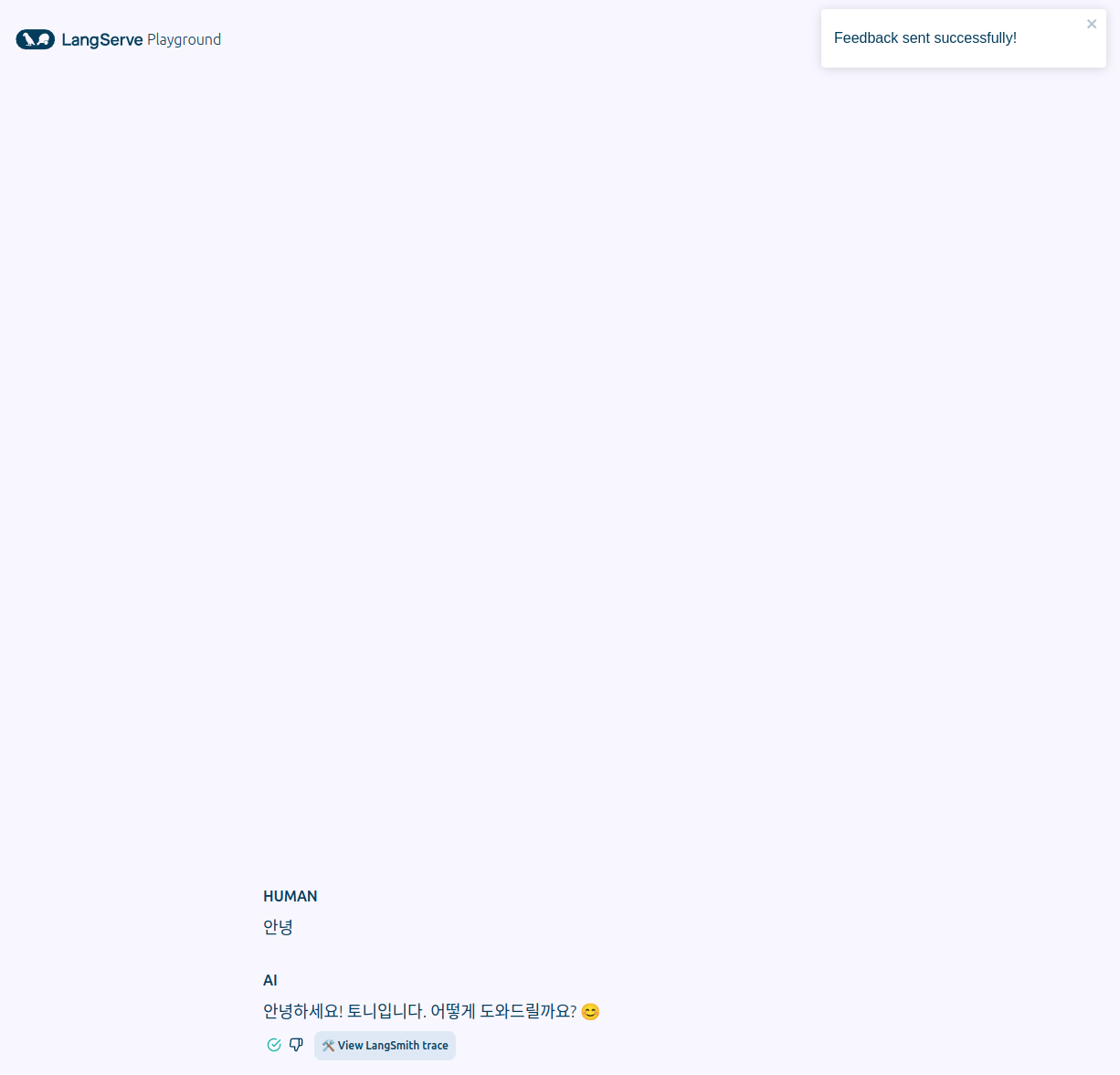
6. LangSmith trace
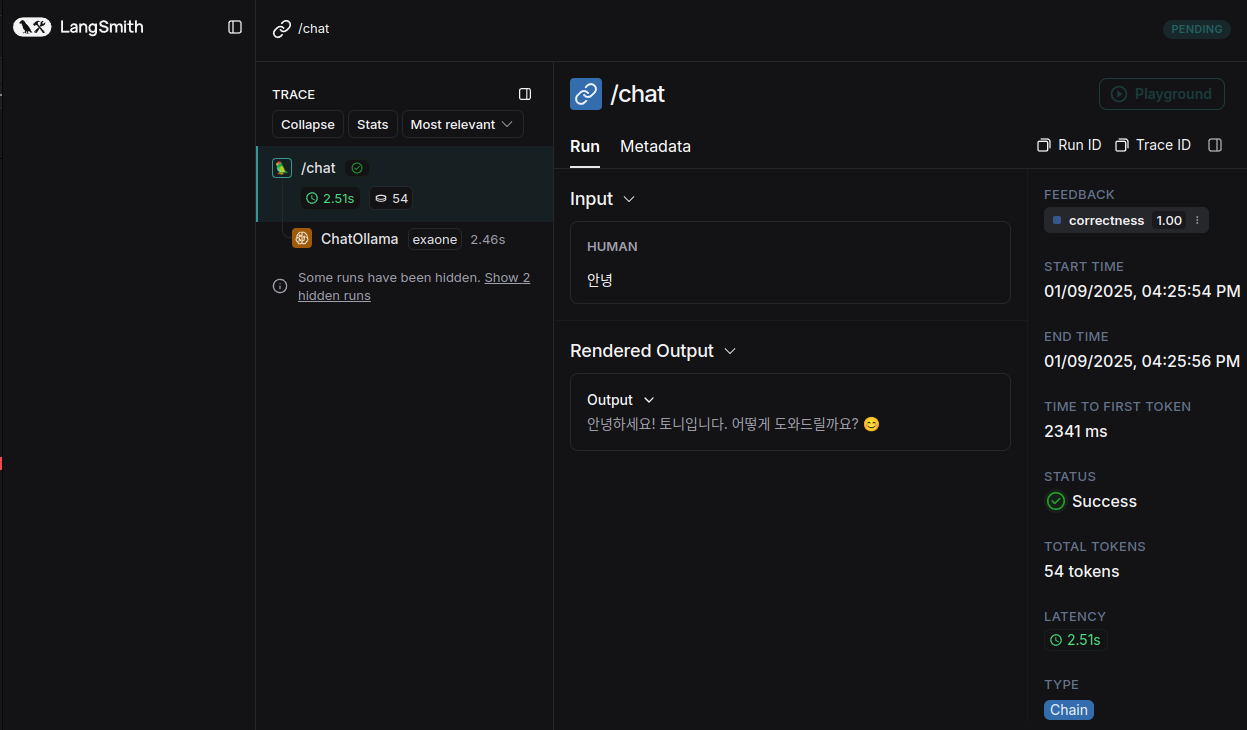
7. 기타 route 확인
http://localhost:8000/chat/playground/
http://localhost:8000/translate/playground/
http://localhost:8000/llm/playground/
http://localhost:8000/topic/playground/
http://localhost:8000/rag/playground/
8. ngrok (Public Web serve)
ngrok는 로컬에서 실행 중인 애플리케이션(예: 웹 서버, API 서버 등)을 공인 인터넷에서 접근 가능하도록 임시 URL(도메인)을 할당해주는 서비스입니다. 쉽게 말해, 개발자가 로컬 환경에서 동작하는 앱을 외부 사용자에게 시연하거나 테스트 용도로 공개할 때 유용합니다.
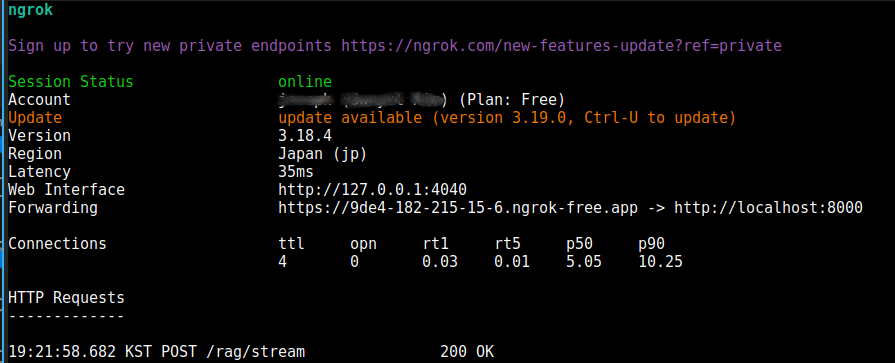
ngrok http localhost:8000
-> 'Forwarding' url 을 제공하여 public url 로 serve 가능합니다.
FastAPI 서버를 사용하여 구동하고 있는 langserve 기반 Runnable 을 사용하는 방법입니다.
from langserve import RemoteRunnable
from langchain_teddynote.messages import stream_response
# 서버 주소 설정(localhost 기준)
# rag_chain = RemoteRunnable("http://0.0.0.0:8000/rag")
rag_chain = RemoteRunnable("https://9de4-182-215-15-6.ngrok-free.app/rag")
# 체인 실행
answer = rag_chain.stream("삼성전자가 개발한 생성형 AI 의 이름은?")
stream_response(answer)
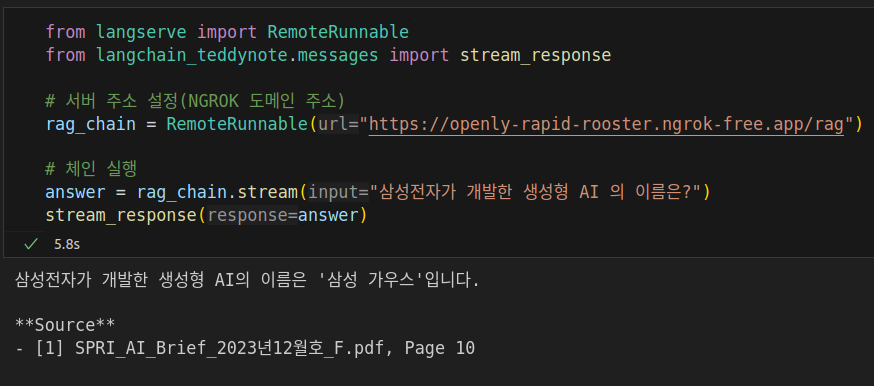
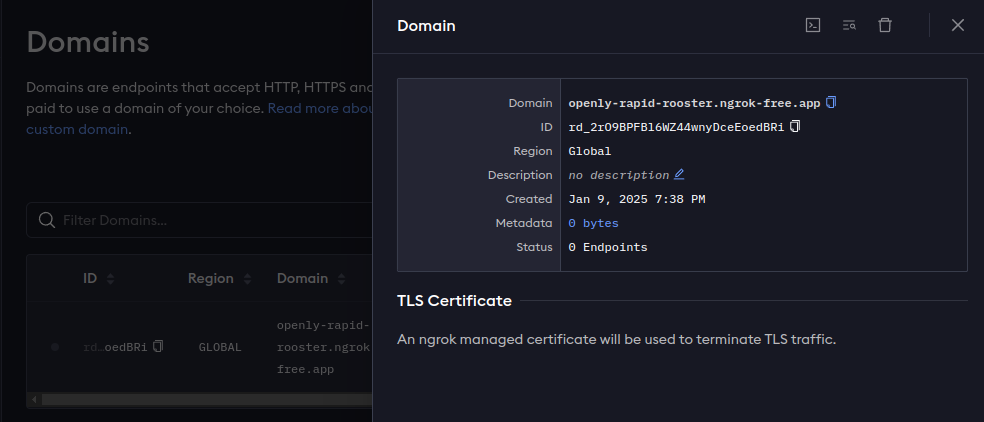
고정 도메인 생성
ngrok http --url=openly-rapid-rooster.ngrok-free.app 8000
from langserve import RemoteRunnable
from langchain_teddynote.messages import stream_response
# 서버 주소 설정(NGROK 도메인 주소)
rag_chain = RemoteRunnable("https://openly-rapid-rooster.ngrok-free.app/rag")
# 체인 실행
answer = rag_chain.stream("삼성전자가 개발한 생성형 AI 의 이름은?")
stream_response(answer)