

토니의 연습장
RLHF / DPO (ft. Pretrained -> SFT -> Reward -> Final model) 본문
AI 일반/모델, 아키텍처, 구현
RLHF / DPO (ft. Pretrained -> SFT -> Reward -> Final model)
bellmake 2025. 9. 5. 13:17
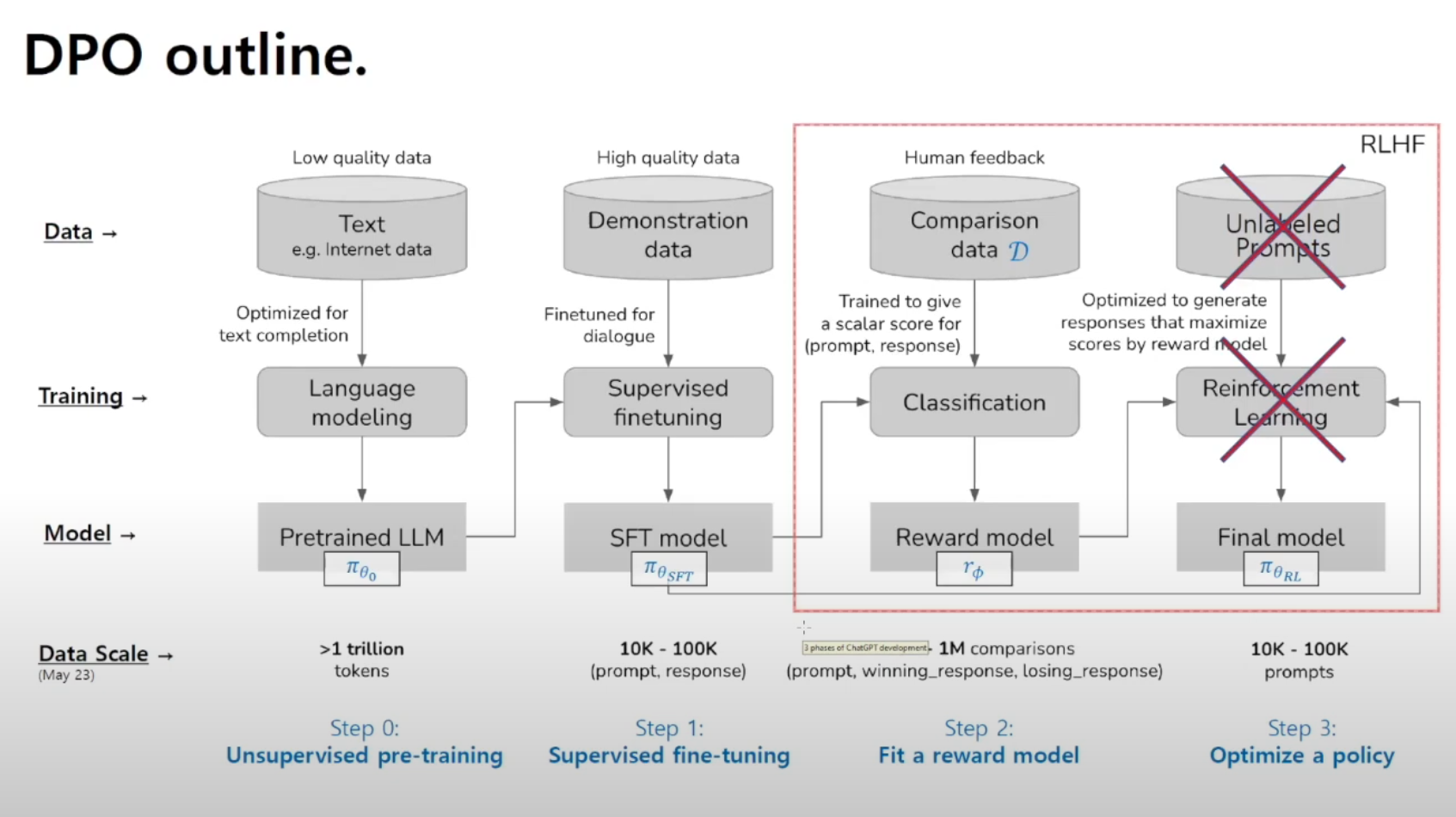
1. Step 0: Unsupervised pre-training (비지도 사전 학습)
- 데이터: 저품질의 대규모 인터넷 텍스트 (> 1조 토큰).
- 훈련: 언어모델링 (다음 단어 예측).
- 결과 모델: Pretrained LLM (πθ₀).
→ GPT 같은 대형 언어모델의 기본 뼈대가 여기서 만들어짐.
2. Step 1: Supervised fine-tuning (지도 미세 조정)
- 데이터: 고품질 시연 데이터 (human demonstration, 즉 사람이 직접 작성한 좋은 대화 예시).
- 훈련: Supervised finetuning (모범적인 답변으로 모델을 미세 조정).
- 결과 모델: SFT 모델 (πθSFT).
→ 기본 모델보다 대화형 태스크에 맞게 "훈련된 모델"이 됨.
3. Step 2: Fit a reward model (보상 모델 학습)
- 데이터: 비교 데이터 (Comparison data, 사람이 두 개의 응답 중 더 좋은 것을 선택).
- 훈련: Classification 모델로 (prompt, winning response, losing response)를 입력받아 점수를 매기는 보상 모델(rφ)을 학습.
- 결과 모델: Reward model.
→ 이제 모델의 응답 품질을 수치(스칼라 점수)로 평가할 수 있게 됨.
4. Step 3: Optimize a policy (정책 최적화)
- 데이터: 라벨 없는 프롬프트 (Unlabeled prompts, 그냥 다양한 질문).
- 훈련: Reinforcement Learning (강화학습). Reward model이 매긴 점수를 기준으로 학습.
- 결과 모델: Final model (πθRL).
→ 사람 피드백을 반영해서 "더 바람직한 답변"을 하는 최종 모델이 완성됨.
데이터 규모
- 사전 학습: > 1조 토큰
- SFT: 1만 ~ 10만 쌍 (prompt-response)
- 보상모델: 10만 ~ 100만 비교 데이터
- RLHF 최종 학습: 1만 ~ 10만 프롬프트
✅ 요약:
- 먼저 대규모 텍스트로 기본 언어모델을 만든다.
- 사람이 직접 작성한 예시로 지도학습 미세조정을 한다.
- 사람이 "어떤 답변이 더 좋은지" 비교한 데이터를 바탕으로 보상모델을 만든다.
- 이 보상모델을 활용해서 강화학습을 통해 최종 모델을 완성한다.



- “학습 시, reward 간의 차이만 고려.”
→ 보상 모델을 학습할 때, 절대적인 보상값이 아니라 두 응답 간 상대적인 보상 차이만 사용한다는 의미야. (예: 응답 A가 B보다 낫다) - “prompt마다 실제 rϕr_\phi는 임의의 방향으로 shift할 가능성 존재.”
→ 보상 함수 rϕr_\phi가 각 프롬프트마다 일정한 기준선(absolute scale)을 가지지 않고, 임의의 offset이나 shift가 생길 수 있다는 뜻이야. 즉, 보상의 절대 크기에는 의미가 없고 상대적 순위만 중요하기 때문에, 프롬프트마다 전체 보상 분포가 이동할 수 있음. - 불안정성: 보상 모델이 프롬프트별로 기준선을 다르게 잡아버리면, 정책(policy) 모델 학습 시 안정성이 떨어질 수 있음.
- 자유도 증가: “degree of freedom”이 늘어난다는 건, 보상 모델이 꼭 필요한 방향만 학습하지 않고 불필요한 변화를 가져올 수 있다는 문제를 뜻함.
- 실무적 해석: 결국 PPO 기반 RLHF는 이런 reward shift 문제 때문에 불안정성이 생기고, policy 모델이 최적화되기 어렵다는 점을 강조.



참고 : https://youtu.be/3M9WHSHMrY0
'AI 일반 > 모델, 아키텍처, 구현' 카테고리의 다른 글
| GPT/Llama 아키텍처 (0) | 2025.09.18 |
|---|---|
| LLM train/eval/generate 간단한 예시 (0) | 2025.09.18 |
| SSL (Self-Supervised Learning) (1) | 2025.08.26 |
| 실무에서의 Embedding 모델 종류 (Text Embedding) (0) | 2025.07.17 |
| Transformer vs LLaMA 모델 비교 (0) | 2025.06.17 |
'AI 일반/모델, 아키텍처, 구현' Related Articles
more

