

토니의 연습장
RAG - AI Agent 예시 본문
*참고 : llm_call, llm_call_async functino 은 가장 하단의 utils.py 참고
1. 프롬프트 체이닝 (Prompt Chaining)
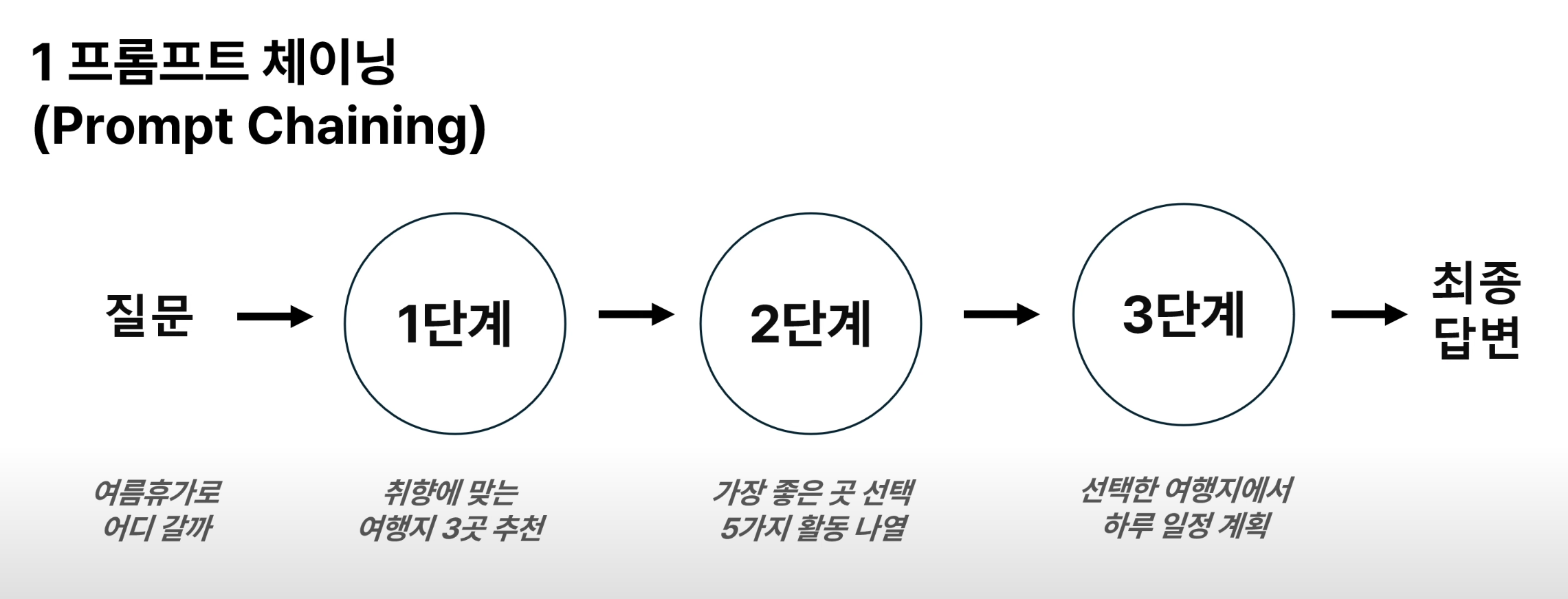
prompt_chaining.py
from typing import List
from utils import llm_call
def prompt_chain_workflow(initial_input: str, prompt_chain: List[str]) -> List[str]:
response_chain = []
response = initial_input
for i, prompt in enumerate(prompt_chain, 1):
print(f"\n==== 단계 {i} ====\n")
final_prompt = f"{prompt}\n사용자 입력:\n{response}"
print(f"🔹 프롬프트:\n{final_prompt}\n")
response = llm_call(final_prompt)
response_chain.append(response)
print(f"✅ 응답:\n{response}\n")
return response_chain
## 처음 입력값을 계속 유지해야 하는 경우!
def prompt_chain_workflow_2(initial_input: str, prompt_chain: List[str]) -> List[str]:
response_chain = []
response = initial_input
for i, prompt in enumerate(prompt_chain, 1):
print(f"\n==== 단계 {i} ====\n")
final_prompt = f"{prompt}\n\n🔹 문맥(Context):\n{response}\n🔹 사용자 입력: {initial_input}"
print(f"🔹 프롬프트:\n{final_prompt}\n")
response = llm_call(final_prompt)
response_chain.append(response)
print(f"✅ 응답:\n{response}\n")
return response_chain
initial_input ="""
나는 여름 휴가를 계획 중이야. 따뜻한 날씨를 좋아하고, 자연 경관과 역사적인 장소를 둘러보는 걸 좋아해.
어떤 여행지가 나에게 적합할까?
"""
# 프롬프트 체인: LLM이 단계적으로 여행을 계획하도록 유도
prompt_chain = [
## 여행 후보지 3곳을 추천하고 그 이유를 설명
"""사용자의 여행 취향을 바탕으로 적합한 여행지 3곳을 추천하세요.
- 먼저 사용자가 입력한 희망사항을 요약해줘
- 사용자가 입력한 희망사항을 반영해서 왜 적합한 여행지인지 설명해주세요
- 각 여행지의 기후, 주요 관광지, 활동 등을 설명하세요.
""",
## 여행지 1곳을 선택하고 활동 5가지 나열
"""다음 여행지 3곳 중 하나를 선택하세요. 선택한 여행지 알려주세요. 그리고 선택한 이유를 설명해주세요.
- 해당 여행지에서 즐길 수 있는 주요 활동 5가지를 나열하세요.
- 활동은 자연 탐방, 역사 탐방, 음식 체험 등 다양한 범주에서 포함되도록 하세요.
""",
## 선택한 여행지에서 하루 일정 계획
"""사용자가 하루 동안 이 여행지에서 시간을 보낼 계획입니다.
- 오전, 오후, 저녁으로 나누어 일정을 짜고, 각 시간대에 어떤 활동을 하면 좋을지 설명하세요.
""",
]
responses = prompt_chain_workflow_2(initial_input,prompt_chain)
final_answer = responses[-1]
print(final_answer)
2. 라우팅 (Routing)
ex) 질문 난이도/깊이에 따라 다른 모델 활용하기
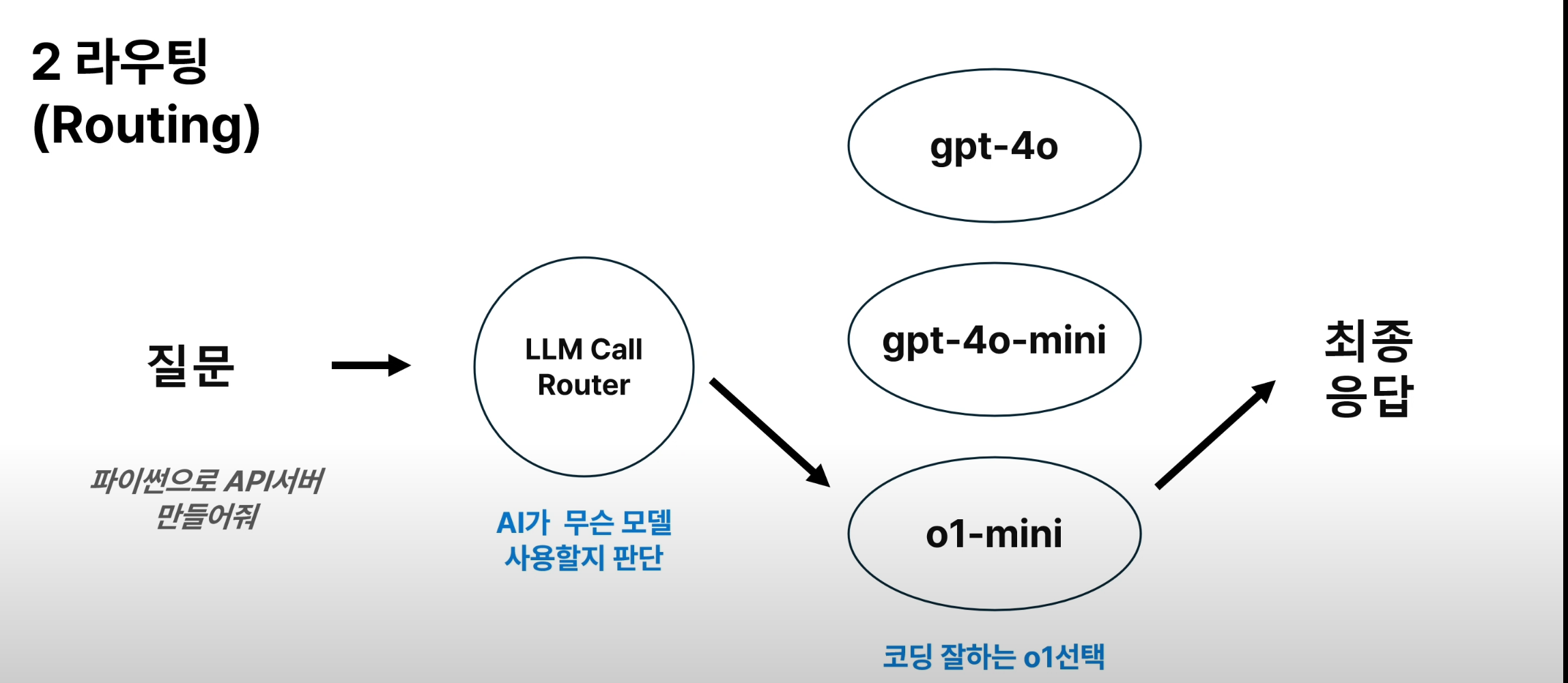
routing.py
from utils import llm_call
def run_router_workflow(user_prompt : str):
router_prompt = f"""
사용자의 프롬프트/질문: {user_prompt}
각 모델은 서로 다른 기능을 가지고 있습니다. 사용자의 질문에 가장 적합한 모델을 선택하세요:
- gpt-4o: 일반적인 작업에 가장 적합한 모델 (기본값)
- o1-mini: 코딩 및 복잡한 문제 해결에 적합한 모델
- gpt-4o-mini: 간단한 사칙연산 등의 작업에 적합한 모델
모델명만 단답형으로 응답하세요
"""
print(router_prompt)
selected_model = llm_call(router_prompt)
print("선택한 모델", selected_model)
response = llm_call(user_prompt, model = selected_model)
print(response)
return response
query1 = "1더하기 2는 뭐지?"
print(query1)
response = run_router_workflow(query1)
query2 = "리스본 여행일정을 짜줘"
print(query2)
response = run_router_workflow(query2)
query3 = "파이썬으로 API 웹서버를 만들어줘"
print(query3)
response = run_router_workflow(query3)
3. 병렬처리 (Parallelization)
ex) 한번에 여러 모델 응답 참고하기
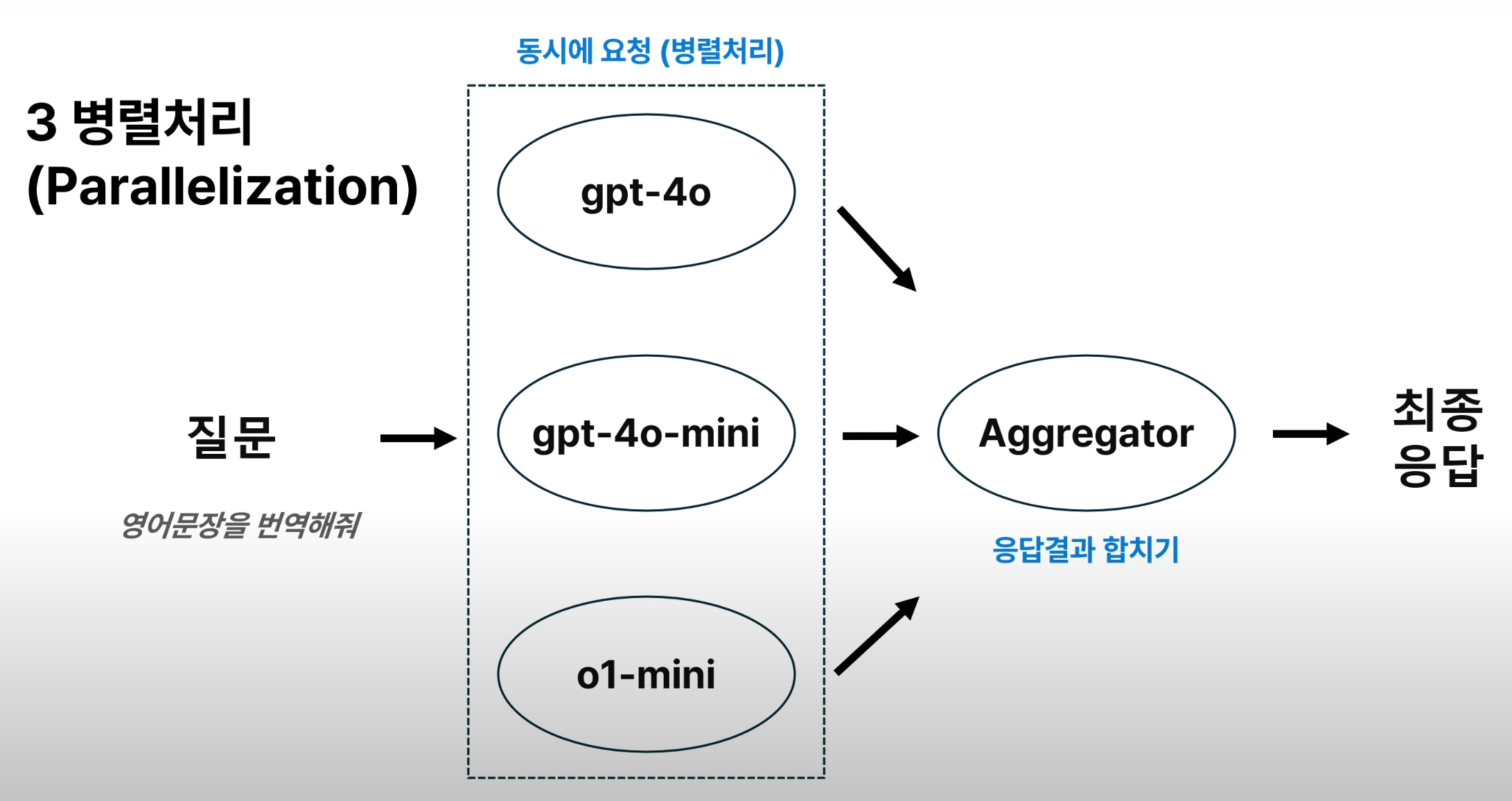
parallel.py
import asyncio
from utils import llm_call_async
async def run_llm_parallel(prompt_details):
tasks = [llm_call_async(prompt['user_prompt'], prompt['model']) for prompt in prompt_details]
responses = []
for task in asyncio.as_completed(tasks):
result = await task
print("LLM 응답 완료:", result)
responses.append(result)
return responses
async def main():
question = ("아래 문장을 자연스러운 한국어로 번역해줘:\n"
"\"Do what you can, with what you have, where you are.\" — Theodore Roosevelt")
parallel_prompt_details = [
{"user_prompt": question, "model": "gpt-4o"},
{"user_prompt": question, "model": "gpt-4o-mini"},
{"user_prompt": question, "model": "o1-mini"},
]
responses = await run_llm_parallel(parallel_prompt_details)
aggregator_prompt = ("다음은 여러 개의 AI 모델이 사용자 질문에 대해 생성한 응답입니다.\n"
"당신의 역할은 이 응답들을 모두 종합하여 최종 답변을 제공하는 것입니다.\n"
"일부 응답이 부정확하거나 편향될 수 있으므로, 신뢰성과 정확성을 갖춘 응답을 생성하는 것이 중요합니다.\n\n"
"사용자 질문:\n"
f"{question}\n\n"
"모델 응답들:")
for i in range(len(parallel_prompt_details)):
aggregator_prompt += f"\n{i+1}. 모델 응답: {responses[i]}\n"
print("---------------------------종합 프롬프트:-----------------------\n", aggregator_prompt)
final_response = await llm_call_async(aggregator_prompt, model="gpt-4o")
print("---------------------------최종 종합 응답:-----------------------\n", final_response)
# 비동기 main 함수 실행
asyncio.run(main())
4. 오케스트레이터-워커 (Orchestrator - Workers)
ex) 하위 질문 생성해서 리서치하기

orchestrator_subagents.py
import asyncio
import json
from utils import llm_call, llm_call_async
# 병렬 처리를 위한 함수
async def run_llm_parallel(prompt_list):
tasks = [llm_call_async(prompt) for prompt in prompt_list]
responses = []
for task in asyncio.as_completed(tasks):
result = await task
responses.append(result)
return responses
# 파이썬 f string에서는 {} 1개는 변수, JSON에서는 2개를 사용해야 함
def get_orchestrator_prompt(user_query):
return f"""
다음 사용자 질문을 분석하고, 이를 3개의 관련된 하위 질문으로 분해하십시오:
다음 형식으로 응답을 제공하십시오:
{{
"analysis": "사용자 질문에 대한 이해를 상세히 설명하고, 작성한 하위 질문들의 근거를 설명하십시오.",
"subtasks": [
{{
"description": "이 하위 질문의 초점과 의도를 설명하십시오.",
"sub_question": "질문 1"
}},
{{
"description": "이 하위 질문의 초점과 의도를 설명하십시오.",
"sub_question": "질문 2"
}}
// 필요에 따라 추가 하위 질문 포함
]
}}
최대 3개의 하위 질문을 생성하세요
사용자 질문: {user_query}
"""
def get_worker_prompt(user_query, sub_question, description):
return f"""
다음 사용자 질문에서 파생된 하위 질문을 다루는 작업을 맡았습니다:
원래 질문: {user_query}
하위 질문: {sub_question}
지침: {description}
하위 질문을 철저히 다루는 포괄적이고 상세한 응답을 해주세요
"""
async def orchestrate_task(user_query):
"""
오케스트레이터를 실행하여 원래 질문을 하위 질문으로 분해하고,
각각의 하위 질문을 병렬적으로 실행하여 종합적인 응답을 생성합니다.
"""
# 1단계 : 사용자 질문 기반으로 여러 질문 도출
orchestrator_prompt = get_orchestrator_prompt(user_query)
print("\n============================orchestrator prompt============================\n")
print(orchestrator_prompt)
orchestrator_response = llm_call(orchestrator_prompt, model="gpt-4o")
# 응답 결과 (1단계) 출력
print("\n============================orchestrator response==========================\n")
print(orchestrator_response)
response_json = json.loads(orchestrator_response.replace('```json', '').replace('```', ''))
analysis = response_json.get("analysis", "")
sub_tasks = response_json.get("subtasks", [])
# 2단계 : 각 하위질문에 대한 LLM 호출
worker_prompts = [get_worker_prompt(user_query, task["sub_question"], task["description"]) for task in sub_tasks]
print("\n============================worker prompts==========================\n")
for prompt in worker_prompts:
print(prompt)
worker_responses = await run_llm_parallel(worker_prompts)
# 응답결과(2단계) 출력
print("\n============================worker responses==========================\n")
for response in worker_responses:
print(response)
# 3단계 : 하위질문 응답 종합 및 LLM 호출
aggregator_prompt = f"""아래는 사용자의 원래 질문에 대해서 하위 질문을 나누고 응답한 결과입니다.
아래 질문 및 응답내용을 포함한 최종 응답을 제공해주세요.
## 요청사항
- 하위질문 응답내용이 최대한 포괄적이고 상세하게 포함되어야 합니다
사용자의 원래 질문:
{user_query}
하위 질문 및 응답:
"""
for i in range(len(sub_tasks)):
aggregator_prompt += f"\n{i+1}. 하위 질문: {sub_tasks[i]['sub_question']}\n"
aggregator_prompt += f"\n 응답: {worker_responses[i]}\n"
print("\n============================aggregator prompt==========================\n")
print(aggregator_prompt)
final_response = llm_call(aggregator_prompt, model="gpt-4o")
return final_response
async def main():
user_query = "AI는 미래 일자리에 어떤 영향을 미칠까?"
# CASE 1 : 그냥 질문했을 때
print("\n============================CASE 1==========================\n")
print(llm_call(user_query,model="gpt-4o"))
# CASE 2 : 오케스트레이터 패턴으로 질문했을 때
print("\n============================CASE 2==========================\n")
final_output = await orchestrate_task(user_query)
# 최종 응답 생성
print("\n============================최종응답==========================\n")
print(final_output)
asyncio.run(main())
5. 평가-최적화 (Evaluator - Optimizer)
ex) 피드백/개선 자동화
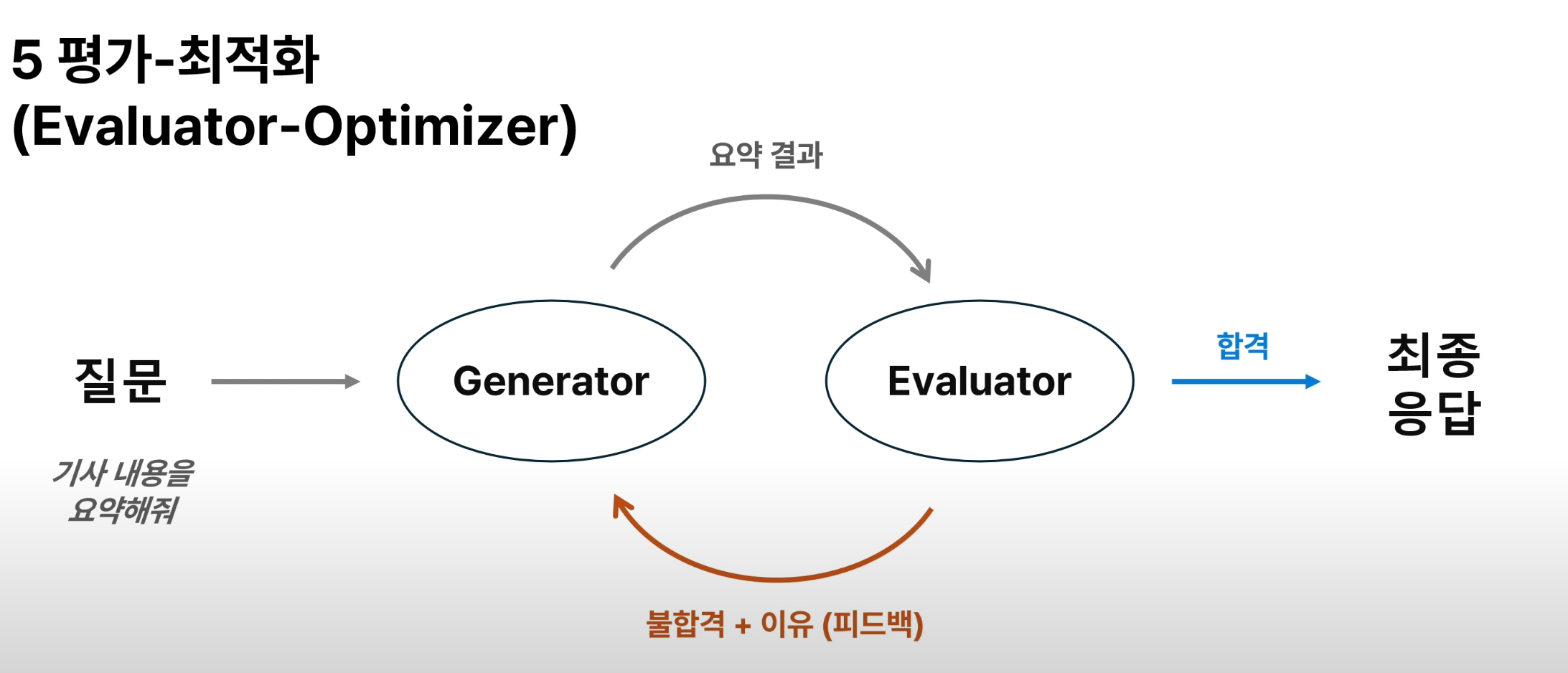
evaluator_optimizer.py
from utils import llm_call
def loop_workflow(user_query, evaluator_prompt, max_retries=5) -> str:
"""평가자가 생성된 요약을 통과할 때까지 최대 max_retries번 반복."""
retries = 0
while retries < max_retries:
print(f"\n========== 📝 요약 프롬프트 (시도 {retries + 1}/{max_retries}) ==========\n")
print(user_query)
summary = llm_call(user_query, model="gpt-4o-mini")
print(f"\n========== 📝 요약 결과 (시도 {retries + 1}/{max_retries}) ==========\n")
print(summary)
final_evaluator_prompt = evaluator_prompt + summary
evaluation_result = llm_call(final_evaluator_prompt, model="gpt-4o").strip()
print(f"\n========== 🔍 평가 프롬프트 (시도 {retries + 1}/{max_retries}) ==========\n")
print(final_evaluator_prompt)
print(f"\n========== 🔍 평가 결과 (시도 {retries + 1}/{max_retries}) ==========\n")
print(evaluation_result)
if "평가결과 = PASS" in evaluation_result:
print("\n✅ 통과! 최종 요약이 승인되었습니다.\n")
return summary
retries += 1
print(f"\n🔄 재시도 필요... ({retries}/{max_retries})\n")
# If max retries reached, return last attempt
if retries >= max_retries:
print("❌ 최대 재시도 횟수 도달. 마지막 요약을 반환합니다.")
return summary # Returning the last attempted summary, even if it's not perfect.
# Updating the user_query for the next attempt with full history
user_query += f"{retries}차 요약 결과:\n\n{summary}\n"
user_query += f"{retries}차 요약 피드백:\n\n{evaluation_result}\n\n"
def main():
## 기사 링크 : https://zdnet.co.kr/view/?no=20250213091248
input_article = """
오픈AI가 몇 주 안에 새로운 모델인 'GPT-4.5'를 출시하며 분산돼 있던 생성형 인공지능(AI) 모델을 통합키로 했다. 추론용 모델인 'o' 시리즈를 정리하고 비(非)추론 모델인 'GPT' 시리즈로 합칠 예정이다.
13일 업계에 따르면 샘 알트먼 오픈AI 최고경영자(CEO)는 지난 12일 자신의 X(옛 트위터)에 'GPT-4.5'를 조만간 출시할 것이라고 밝혔다. 현 세대인 'GPT-4o'의 뒤를 잇는 마지막 '비추론 AI'로, 내부적으로는 '오라이언(Orion)'이라고 불렸다.
현재 챗GPT 이용자를 비롯한 오픈AI의 고객들은 'GPT-4o', 'o1', 'o3-미니', 'GPT-4' 등 모델들을 각자 선택해 활용하고 있다. 최신 모델은 'GPT-4'를 개선한 'GPT-4o'로, 'GPT-4'는 2023년 하반기, 'GPT-4o'는 2024년 상반기 출시됐다.
오픈AI는 'GPT-5'도 지난해 공개하려고 했으나, 예상보다 저조한 성과를 거둬 출시가 연기된 상태다. 이에 그간 연산 시간을 늘려 성능을 높인 'o'시리즈 추론 모델을 새롭게 내세웠다.
샘 알트먼 CEO는 "이후 공개될 'GPT-5'부터는 추론 모델인 'o'시리즈와 'GPT'를 통합하겠다"며 "모델과 제품라인이 복잡해졌음을 잘 알고 있고, 앞으로는 각 모델을 선택해 사용하기보다 그저 잘 작동하길 원한다"고 말했다.
"""
user_query = f"""
당신의 목표는 주어진 기사를 요약하는 것입니다.
아래 주어진 기사 내용을 요약해주세요.
이전 시도의 요약과 피드백이 있다면, 이를 반영하여 개선된 요약을 작성하세요.
기사 내용:
{input_article}
"""
evaluator_prompt = """
다음 요약을 평가하십시오:
## 평가기준
1. 핵심 내용 포함 여부
- 원문의 핵심 개념과 논리적 흐름이 유지되어야 합니다.
- 불필요한 세부 사항은 줄이되, 핵심 정보가 누락되면 감점 요인입니다.
- 단어 선택이 다소 달라도, 주요 개념과 의미가 유지되면 PASS 가능합니다.
- 원문의 중요 개념 15% 이상이 빠졌다면 FAIL입니다.
2. 정확성 & 의미 전달
- 요약이 원문의 의미를 왜곡하지 않고 정확하게 전달해야 합니다.
- 숫자, 인명, 날짜 등 객관적 정보가 틀리면 FAIL입니다.
- 문장이 다르게 표현되었더라도 원문의 의미를 유지하면 PASS 가능합니다.
- 논리적 비약이 크거나 잘못된 해석이 포함되면 FAIL입니다.
3. 간결성 및 가독성
- 문장이 과하게 길거나 반복적이면 감점 요인입니다.
- 직역체 표현은 가독성을 해치지 않으면 허용 가능하지만, 지나치면 FAIL입니다.
- 일부 단어의 표현 방식이 달라도 자연스럽다면 PASS 가능합니다.
- 문장이 지나치게 어색해서 독해가 어렵다면 FAIL입니다.
4. 문법 및 표현
- 맞춤법, 띄어쓰기 오류가 5개 이상이면 FAIL입니다.
- 사소한 문법 실수는 감점 요인이나, 의미 전달에 영향을 주면 FAIL입니다.
- 문장이 비문이거나 문맥상 어색한 표현이 많으면 FAIL입니다.
## 평가결과 응답예시
- 모든 기준이 충족되었으면 "평가결과 = PASS"를 출력하세요.
- 수정이 필요한 경우, 구체적인 문제점을 지적하고 반드시 개선 방향을 제시하세요.
- 중대한 오류가 있다면 "평가결과 = FAIL"을 출력하고, 반드시 주요 문제점을 설명하세요.
요약 결과 :
"""
final_summary = loop_workflow(user_query, evaluator_prompt, max_retries=5)
print("\n✅ 최종 요약:\n", final_summary)
if __name__ == "__main__":
main()
참고) utils.py
import re
from openai import AsyncOpenAI, OpenAI
OPENAI_API_KEY = ""
client = AsyncOpenAI(
api_key=OPENAI_API_KEY,
)
sync_client = OpenAI(
api_key=OPENAI_API_KEY,
)
def llm_call(prompt: str, model: str = "gpt-4o-mini") -> str:
messages = []
messages.append({"role": "user", "content": prompt})
chat_completion = sync_client.chat.completions.create(
model=model,
messages=messages,
)
return chat_completion.choices[0].message.content
async def llm_call_async(prompt: str, model: str = "gpt-4o-mini") -> str:
messages = []
messages.append({"role": "user", "content": prompt})
chat_completion = await client.chat.completions.create(
model=model,
messages=messages,
)
print(model,"완료")
return chat_completion.choices[0].message.content
if __name__ == "__main__":
test = llm_call("안녕")
print(test)
'언어 AI (NLP) > LLM & RAG & Agent' 카테고리의 다른 글
| RAG 성능 테스트를 위한 함수 정의 (0) | 2025.03.06 |
|---|---|
| RAGAS 를 이용한 RAG 평가 (0) | 2025.02.27 |
| RAG 중복문장 제거 (0) | 2025.02.15 |
| gguf/safetensor 로 ollama 모델 만들기 (0) | 2025.02.11 |
| db.add_documents() 특징 (0) | 2025.02.06 |
'언어 AI (NLP)/LLM & RAG & Agent' Related Articles
more
