
토니의 연습장
LoRA (Low Rank Adaptation) 본문

Stable Diffusion 모델을 개인의 custom model로 fine tuning 하기는 쉽지 않습니다.
또한, 자원 및 데이터의 제한 문제와 함께 신규 데이터셋을 통해 재학습 했을 때 발생할 수 있는 문제도 있습니다.
(모델 전체 학습 : 학습의 효율성 문제 / 일부 layer 학습 : 성능의 문제)
이를 해결하기 위해 도입할 수 있는 기법 중 하나가 PEFT 기술 중 하나인 LoRA로써, 이는 대규모 사전학습된 언어 모델을 적용하는 과정에서 fine tuning 하기 위해 NLP에서 가장 먼저 도입되었으며, Fine tuning 학습시간을 감소시키면서도 Base model의 기본 성능을 저해하지 않습니다.
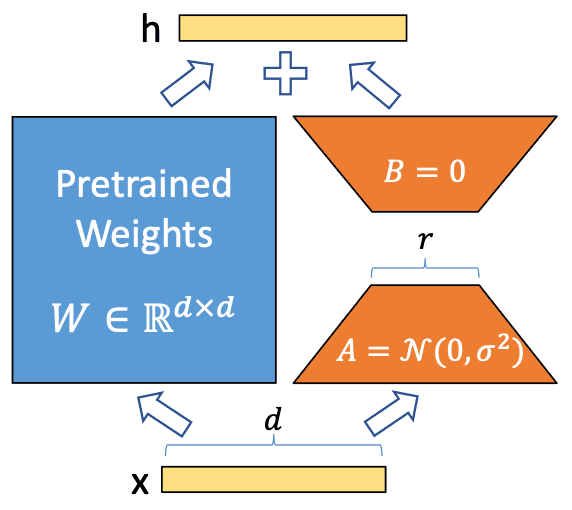
해당 기법의 원리를 간단히 요약하면, 위 그림에서와 같이 Pretrained Weights는 고정하고, Adaptor인 A와 B만 학습하여 효율적으로 output h를 수정 가능하게 됩니다.
위와 같은 LoRA를 Stable Diffusion에 적용하기 위한 방안으로는, Transformer의 self attention 모듈에 적용하고 MLP에는 적용하지 않는 것입니다. 즉, input의 W matrix 적용 부분에서 이를 low rank로 분해하여 LoRA를 적용하는 것입니다.
이렇게 할 경우 메모리 / 스토리지의 사용량이 감소할 뿐만 아니라, 모델 사용자 간의 공유 차원에서도 LoRA 가중치만을 상호 교환받아(LoRA 모델만 배포) 사용할 수 있는 편리함도 증대됩니다.
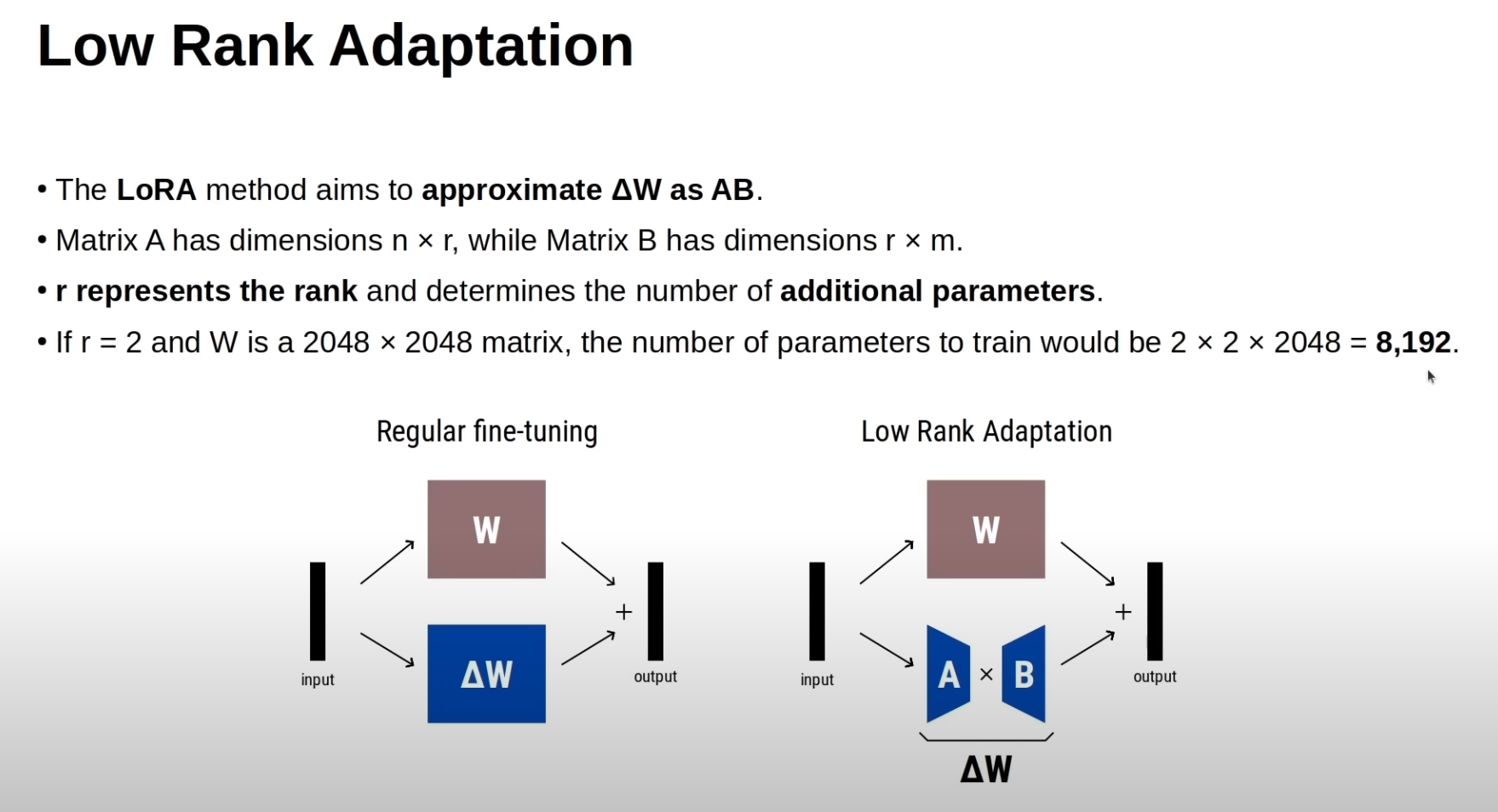
1. 상황 설정
- 원래 학습해야 할 파라미터는 W라는 큰 행렬이고, 크기가 2048 × 2048 → 약 4백만(= 4,194,304) 개의 파라미터가 있습니다.
- LoRA에서는 이 큰 ΔW를 직접 학습하지 않고, 두 개의 작은 행렬 A와 B의 곱으로 근사합니다.
- A의 크기: n × r = 2048 × 2
- B의 크기: r × m = 2 × 2048
2. 파라미터 수 계산
- A의 파라미터 수: 2048 × 2 = 4096
- B의 파라미터 수: 2 × 2048 = 4096
- 합하면: 4096 + 4096 = 8192
즉, 8192개의 파라미터만 학습하면 전체 420만 개짜리 행렬을 근사할 수 있음.
3. 의미
- 파라미터 절약 효과:
전체 파라미터 4,194,304개 → LoRA 사용 시 8192개 (약 512배 적은 수). - 효율적인 미세조정:
모델 전체를 학습시키지 않고, 소량의 파라미터만 학습하여 메모리·계산량을 크게 줄이면서도 효과적으로 모델을 적응(adaptation)시킬 수 있음.

[ 참고 ]
https://chatgpt.com/share/e37ddeb9-9132-42b3-b7d9-dfa1571f921b
https://chatgpt.com/share/68cbb09c-149c-8009-b21f-3928f2fc1323
'비전 AI (VISION) > Stable Diffusion' 카테고리의 다른 글
| FLUX - LoRA (2) | 2025.03.15 |
|---|---|
| Inpainting (1) | 2024.08.24 |
| StableDiffusionPipeline (2) | 2024.08.23 |
| Stable Diffusion 이론 (0) | 2024.08.23 |



